
構造化データとは何か、Googleがリッチリザルトのために構造化データの利用用途や構造化データがトラフィックを増やすのに役立つのかについて説明します。
リッチリザルトとは、通常の検索結果と比べ、青色リンクや多くの視覚的な機能や操作機能が追加された検索結果のことです。
目次
構造化データとは?使用方法は?
Webページの内容を検索エンジン(Googleなど)によりわかりやすく伝えるためにHTMLで記述した情報をタグ付けすることです。構造化データの主な目的は、Webページに関する特定の情報を伝達し、Googleの検索結果でリッチリザルトとして表示されるようにすることです。
| 構造化データ ⇒ Google ⇒ リッチリザルト |
セマンティックWebとは?
構造化データは、セマンティックWebという考え方を実現するためのものです。
セマンティックWebとは、Webページに記述された内容について、それが何を意味するかを表す「情報についての情報」(メタデータ)を一定の規則に従って付加し、コンピュータシステムによる自律的な情報の収集や加工を可能にする構想
IT用語辞書 e-Words
つまり、セマンティックWebとは、これまでの検索エンジンがテキストを単なる「文字」として認識し情報として蓄積していたのに対し、文字列の意味や文脈、背景などまで理解させようとする考え方です。
構造化データのメリット
構造化データのメリットには、検索エンジンがページコンテンツを理解しやすくなること、検索結果にリッチリザルトが表示されるようになること、ウェブページ全体のCTR(クリックスルー率)を高めることができることの3点があります。
通常の検索スニペットとは異なり、より魅力的で視覚的にアピールすることができるため、リッチリザルトの形で表示することができるページは、Googleから多くのオーガニックトラフィックを得ることができます。
構造化データのデメリット
構造化データのデメリットとしては、マークアップに関わる専門知識が必要なこと、デザインの実装や改修に工数がかかることがあります。構造化データを用いても検索結果に必ずリッチスニペットが表示されるものでもないので、サイトのタイプによって”構造化データを用いる基準”を決めることが必要です。
構造化データはマークアップ言語である
構造化データもマークアップ言語の一つです。HTMLのmetaタグと同様に、構造化データもメタデータの一種です。メタデータは、サイト訪問者が直接目にすることはなく、構造化データのコンテンツは、検索エンジンが見るデータです。構造化データによって、検索エンジンは画像やコンテンツの内容を理解しやすくなり、その内容を検索結果に正確に表示することができるようになります。例えば、検索エンジン向けに製品名、レビューコンテンツ、評価、画像をラベル付けすることができます。画像は商品画像として、特定の単語は商品レビューとしてラベル付けされます。
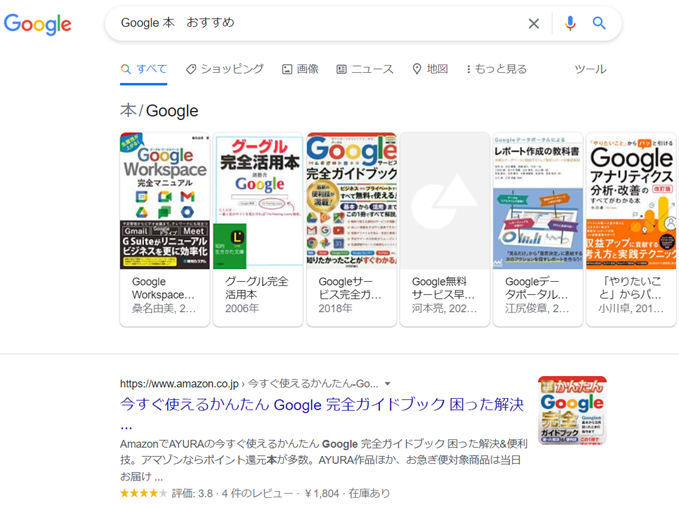
Googleがサポートしている構造化データ
Googleがリッチリザルトとしてサポートしている構造化データは、30種類あります。
以下で項目をご紹介します。
| Article | Book | パンくずリスト |
| カルーセル | Course | 評論家レビュー |
| Dataset | EmployerAggregateRating | Event |
| ファクト | チェック | よくある質問 |
| ハウツー | 画像のライセンス(ベータ版) | JobPosting |
| 職業訓練(ベータ版) | ローカルビジネス | Logo |
| Movie | 給与推定額 | ポッドキャスト |
| Product | Q&A | Recipe |
| クチコミ抜粋 | サイトリンク検索ボックス | ソフトウェア |
| アプリ(ベータ版) | 定期購入とペイウォールコンテンツ | Speakable Video |
よく目にする構造化データとしては、検索結果から直接本が買える「Book」、お店などの営業時間、評価、経路に加え、予約や注文のアクションも表示した「ローカルビジネス」、特定の質問と回答を掲載する「よくある質問」があります。
すべての項目の内容が知りたい方は、Google検索デベロッパーガイドに各項目の説明が掲載されていますのでご覧ください。
構造化データの形式
構造化データを理解する上で、ボキャブラリーとシンタックスの2つの言葉についてきちんと理解しておく必要があります。端的に言うと、ボキャブラリーが値を表し、シンタックスはその記述方法になります。
マークアップできる構造化データの形式/仕様(シンタックス)は、基本的に「JSON-LD」「microdata」「RDFa」の3つがありますが、中でもGoogleは「JSON-LD」を推奨しています。
- JSON-LD(Google推奨)
JSON-LD (JavaScript Object Notation for Linked Data) は、構造化データに使用できる最も一般的なマークアップ・スクリプト。また、Googleが最も好む構造化データのバージョン。JSON-LDの主な利点は、HTMLドキュメントの残りの部分を混乱させることなく、コードのブロックとして実装でき、単にページの<head>または<body>セクションにスクリプトをコピーして貼り付けるだけでページがきれいに構成されます。 - microdata
microdataは、構造化データのページ上の項目と値を個別に強調するタグのセットに基づいています。構造化データのタイプとプロパティは、ページ上に配置可能なitemtypeとitempropのHTML属性によってマークされます。microdataの主な欠点は、JSON-LDによって実装できるコードの1つの大きなブロックとは対照的に、コンテンツのすべてのエンティティまたは属性が、ページのHTMLボディ内で個別にマークされなければならないため、大規模なウェブサイトには適さないことがあります。 - RDFa
RDFa(Resource Description Framework in Attributes)は、構造化データの項目をマークアップするために使用できるHTML5の拡張機能です。Microdataと同様にRDFaはtypeofとpropertyというHTML属性を使って、ページのHTMLボディ内でコンテンツの断片をマークアップします。
構造化データの記述の仕方
構造化データの記述方法は、”HTML上に直接マークアップする方法”と”構造化データマークアップ支援ツール”を用いる方法の主に2つです。
HTML上に直接マークアップする方法
HTML上に直接マークアップする方法としては、以下が記述例です。
▼構造化していない記述例
<div>会社名:プルーヴ株式会社</div>
<div>郵便番号:105-0004</div>
<div>住所:東京都港区新橋5-23-7 三栄ビル2F</div>
<div>電話番号:03-6435-6963</div>
<div>コーポレートサイト:https://gdx-j.com/</div>
▼JSON-LDで記述
<script type=”application/ld+json”>
{
“@context”: “http://schema.org”,
“@type”: “Corporation”,
“name”: “プルーヴ株式会社”,
“address”: {
“@type”: “PostalAddress”,
“postalCode”: “105-0004”,
“addressRegion”: “東京都”,
“addressLocality”: “港区”,
“streetAddress”: “新橋5-23-7 三栄ビル2F”
},
“telephone”: “+8364356963”,
“URL”: “https://gdx-j.com/”
}
</script>
▼microdataで記述
<div itemscope itemtype=”http://schema.org/Corporation”>
<span itemprop=”name”>プルーヴ株式会社</span>
<span itemprop=”address” itemscope itemtype=”http://schema.org/PostalAddress”>
<span itemprop=”postalCode”>105-0004</span>
<span itemprop=”addressRegion”>東京都</span>
<span itemprop=”addressLocality”>港区</span>
<span itemprop=”streetAddress”>新橋5-23-7 三栄ビル2F</span></span>
<span itemprop=”telephone” content=”+8364356963″>03-6435-6963</span>
<span itemprop=”URL”>https://gdx-j.com/</span>
</div>
▼RDFaで記述
<div vocab=”http://schema.org/” typeof=”Corporation”>
<span property=”name”>プルーヴ株式会社</span>
<span property=”address” typeof=”PostalAddress”>
<span property=”postalCode”>105-0004</span>
<span property=”addressRegion”>東京都</span>
<span property=”addressLocality”>港区</span>
<span property=”streetAddress”>新橋5-23-7 三栄ビル2F</span></span>
<span property=”telephone” content=”+8364356963″>03-6435-6963</span>
<span property=”URL”>https://gdx-j.com//</span>
</div>
マークアップ支援ツール
よく使われる構造化データのプロパティは、マークアップのための支援ツールが提供されています。HTMLファイルが直接編集できない場合は、支援ツールを使ってマークアップができます。
ただし、ツールによって対応しているプロパティが異なり、限定されているのでご注意ください。
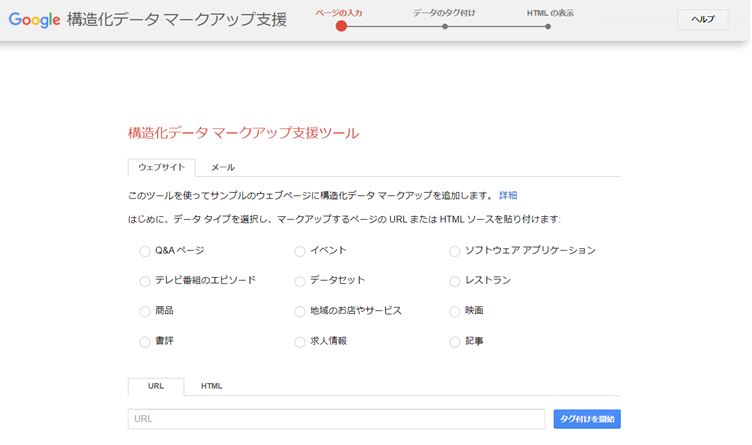
対応プロパティ:Q&A ページ、イベント、ソフトウェア アプリケーション、テレビ番組のエピソード、データセット、レストラン、商品、地域のお店やサービス、映画、書評、求人情報、記事
②データハイライター
構造化データのマークアップからクロールまで一貫して実施できます。利用するには、構造化データをマークアップしたいサイトをあらかじめGoogle Search Consoleに登録する必要があります。
対応プロパティ:記事、イベント、地域のお店やサービス、レストラン、商品、ソフトウェア アプリケーション、映画、テレビ番組のエピソード、書籍
構造化データのガイドラインと検証方法
Googleは、構造化データの品質のガイドラインがあり、公式のサイトでは以下のように記載されています。
すべての構造化データに適用される一般的なガイドラインです。構造化データが Google 検索結果に表示されるようにするには、これらのガイドラインを遵守する必要があります。コンテンツのガイドラインに違反しているページやサイトは、ランクが下がったり、Google 検索のリッチリザルトの対象外としてマークされたりすることがあり、ユーザーに高品質の検索エクスペリエンスを提供し続けることができなくなる場合があります。ページ内でスパム行為のある構造化データまたはコンテンツが見つかった場合、Google はそのページに対して手動による対策をとります。
構造化データに関する一般的なガイドライン
せっかく設定をしてもガイドラインの要件を満たしていなければ表示されないため、要件を満たしているか確認する必要があります。確認用に複数のツールが提供されています。
リッチリザルトテストツールで要件を検証
「リッチリザルトテスト」が利用できます。Googleがリッチリザルトの表示で利用しているプロパティに限り、表示の要件を満たしているかどうかを確認できます。
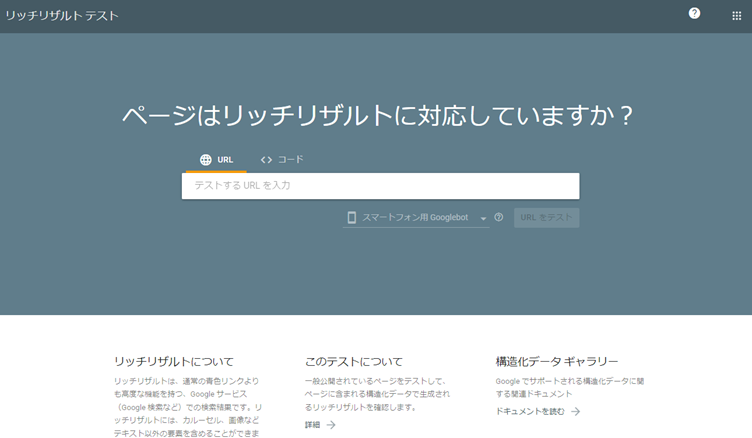
リッチリザルトテストツールの使い方は2種類あります。
①URLを入力でテスト
ページ中央「テストするURLを入力」の欄にURLを記入し、「URLをテスト」をクリックで確認します。
②コード入力でテスト
コードを選択し、「テストするコードを貼り付け」欄に記述したコード自体を検証します。その場でコードを修正が可能です。
Schema Markup Validatorで文法を検証
Schema Markup Validatorを利用します。
リッチリザルトテストツールと同様に、どちらかのコードスニペットまたはURLをコピーして貼り付けると、構造化データマークアップに任意のエラーがあるかどうかを確認することができます。
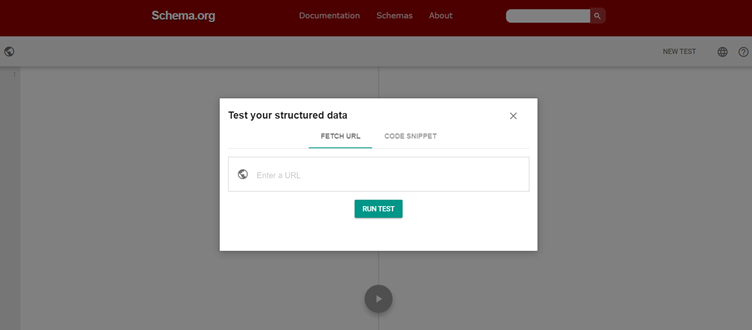
文法の正確さのみを確認するため、Googleが定めるリッチリザルト表示に必須のプロパティが抜けていてもこのツールでは確認できません。
Googleで認識されているか確認
構造化データの導入後に、Google Search Consoleの拡張レポートを利用し、Googleが認識できているか最終確認を実施します。構造化データのプロパティごとに、「エラー」「有効(警告あり)」「有効」のステータスを確認できます。
まとめ
- 構造化データを活用し、リッチリザルトが表示されるようになると、オーガニックの流入を増やし、ウェブページ全体のCTR(クリックスルー率)を高めることができます。
- マークアップも直接記述し、マークアップするのみでなくマークアップ支援ツールを利用し簡単に実装も可能です。
- マークアップ完了後はガイドラインの要件や文法を満たせているかを必ず確認し、リッチリザルト表示されることの確認が重要です。